How I Built a Distributed Crawler for Wikipedia at Scale
Ever wondered how early search engines managed to crawl and index the vast web?
I wanted to explore this challenge by building a search-engine style distributed crawler, targeted at Wikipedia.
The result: a horizontally scalable, event-driven system that can handle 6.4 million+ pages per day on a 24-core VM.
Motivation
Search engines rely on large-scale web crawlers to fetch, parse, and store data.
But building one isn’t trivial — you need to solve:
- High throughput crawling without overwhelming servers
- Deduplication and cycle detection (so you don’t crawl the same page endlessly)
- Scalable architecture that can handle millions of URLs
- Monitoring and observability to debug bottlenecks
This project was my attempt to simulate that — building a distributed system from scratch while applying lessons from real-world architectures.
Tech Stack (At a Glance)
- Python for service logic
- Docker Compose for orchestration (dev & prod)
- RabbitMQ for messaging & load balancing
- PostgreSQL + SQLAlchemy for persistence
- Redis for caching & deduplication
- Prometheus + Grafana + pgAdmin + cAdvisor for monitoring
- Webshare proxies for geo-distributed crawling
Architecture Overview
The system is composed of 7 independent worker services connected through RabbitMQ, each horizontally scalable.
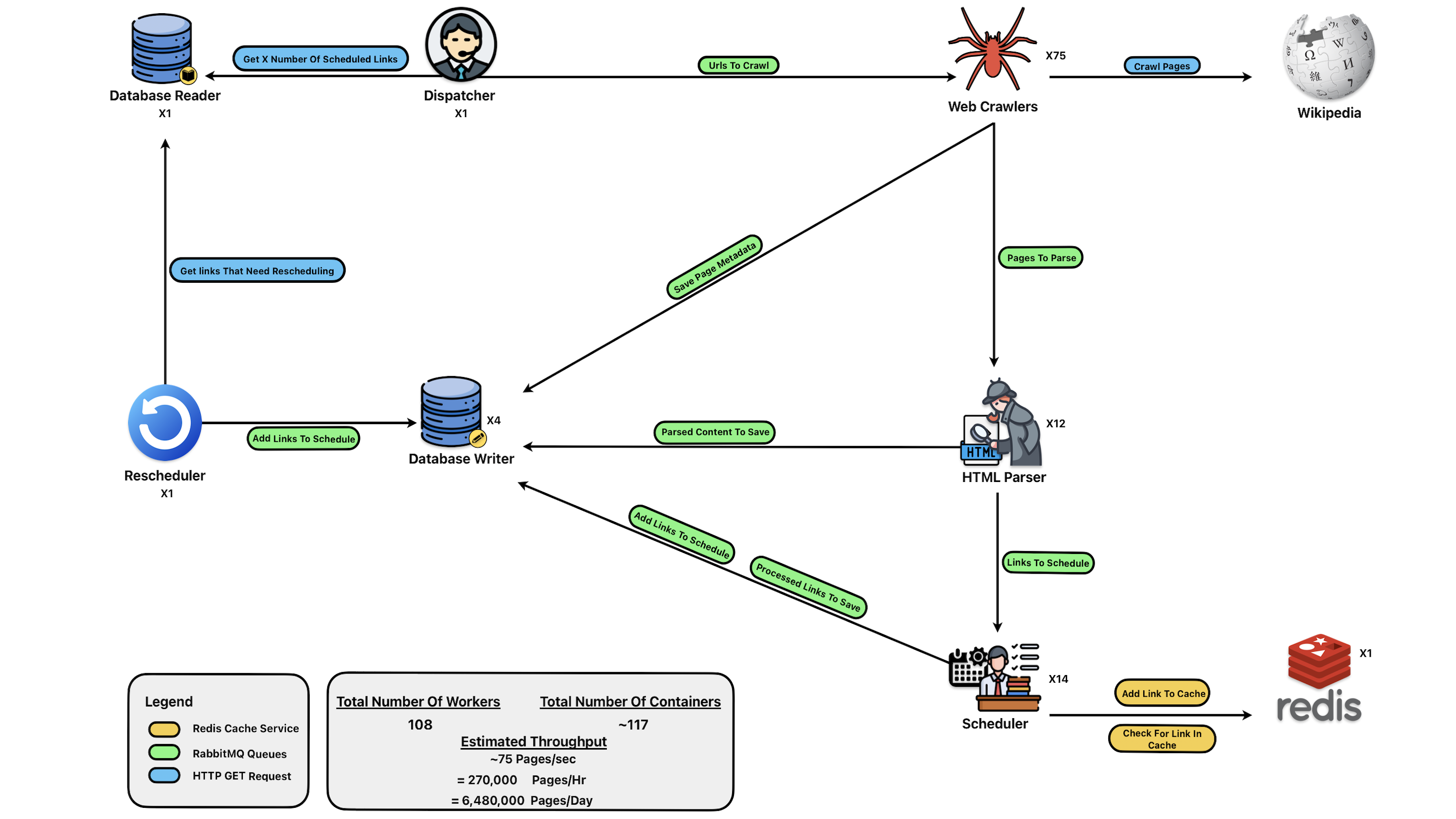
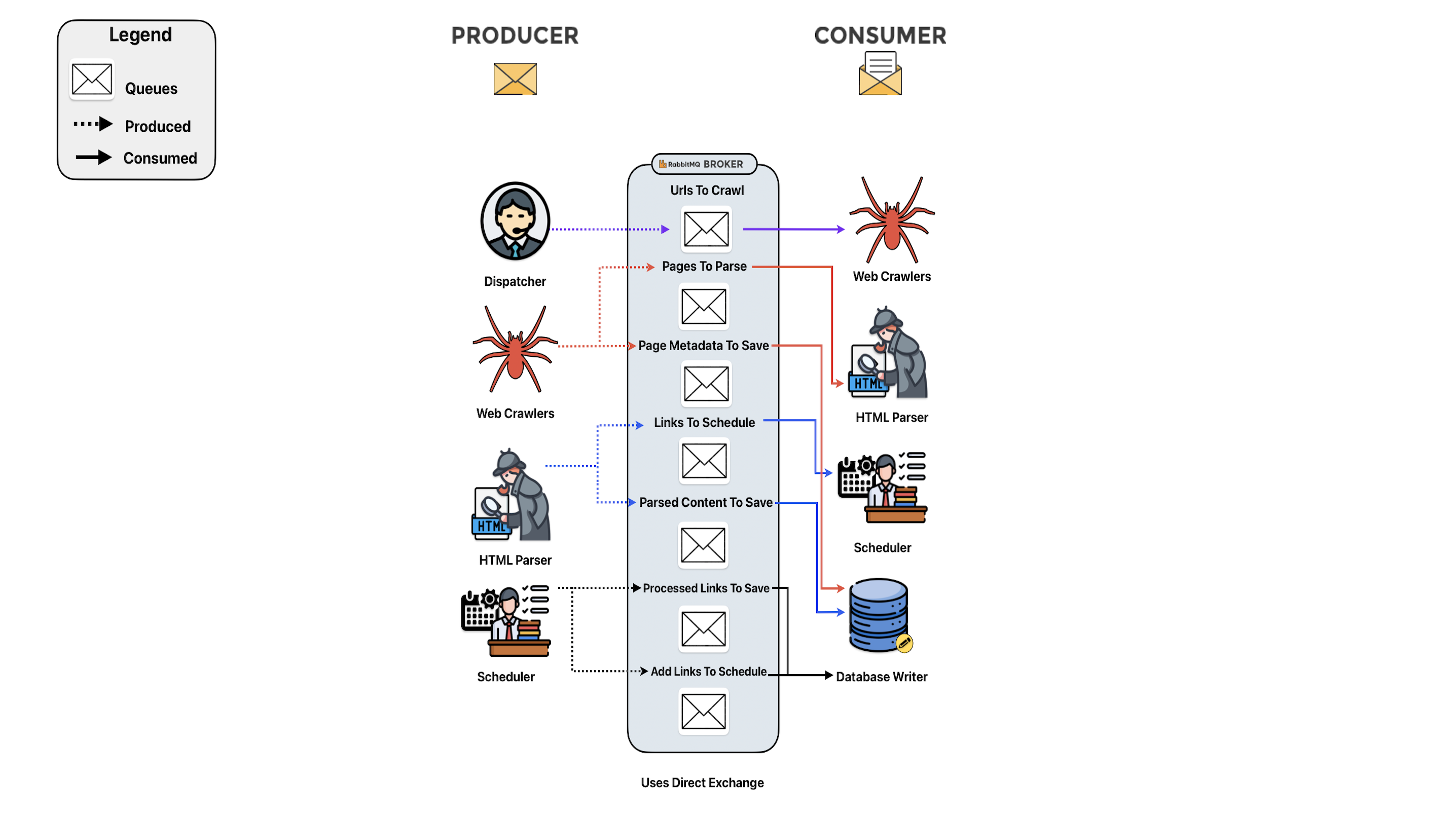
Core Components
- Crawler – Fetches HTML, compresses & stores it, publishes metadata for parsing. (Rate-limited: 1 req/s per crawler)
- Parser – Extracts titles, content, categories, links; publishes parsed data and outbound links.
- Scheduler – Filters, normalizes, dedupes via Redis, respects
robots.txt. - DB Writer – Writes parsed metadata and links into PostgreSQL.
- DB Reader (HTTP API) – Serves read-only queries directly from PostgreSQL.
- Dispatcher – Requests scheduled URLs and pushes them back into RabbitMQ.
- Rescheduler – Periodically re-queues pages for recrawl (~8 days).
Together, these services form a distributed, event-driven pipeline capable of scaling linearly with resources.
Implementation Details
- Scaling with Docker Compose – Each service can be scaled independently (
docker-compose up --scale crawler=75). - Redis Deduplication – Prevents infinite loops and duplicate crawls.
- Rate Limiting – Crawlers throttle at 1 req/sec to respect Wikipedia’s terms.
- Rescheduling – Pages are revisited after ~8 days for freshness.
- Monitoring – Prometheus + Grafana provides dashboards.
- Proxies – Webshare proxies distribute traffic geographically to simulate real-world crawling.
Challenges & Solutions
- Throughput bottlenecks – Solved by scaling crawlers (75+ instances) and distributing load via RabbitMQ.
- Duplicate links – Redis-based deduplication ensures each page is crawled once per cycle.
- Backpressure in queues – Monitored with Prometheus and solved by adjusting parser/writer scaling ratios.
- Monitoring complexity – Built a full observability stack (Prometheus, Grafana, cAdvisor, pgAdmin).
Performance Results
Test Setup:
- Proxmox VM, 24 cores, 32 GB RAM
- Deployment: 117 containers
- Mix of crawlers, parsers, schedulers, writers, and monitoring stack
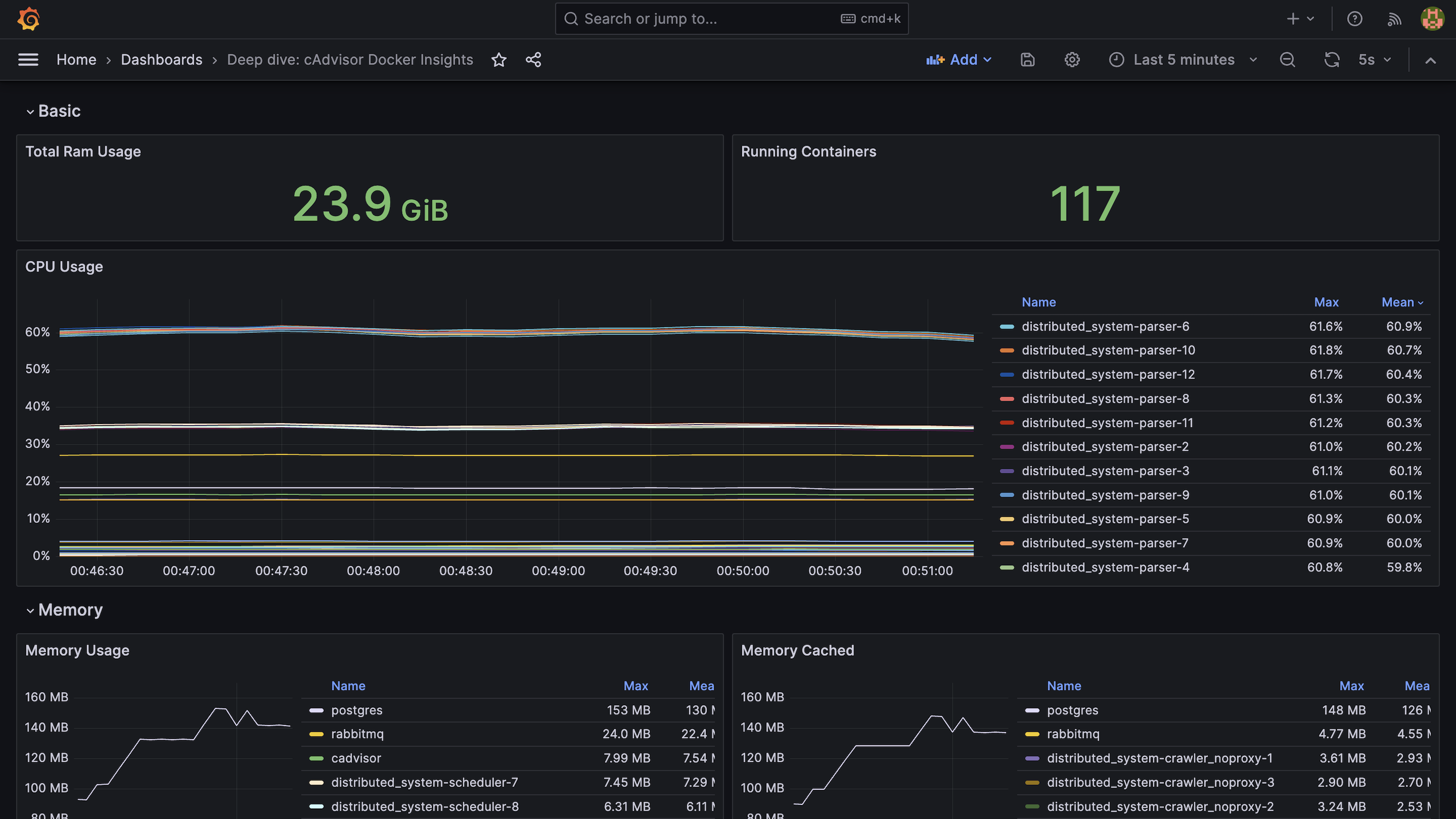
Results:
- ~75 pages/sec throughput
- ~6.48 million pages/day sustained
These results demonstrate the scalability and robustness of the architecture.


Reflection & Roadmap
What worked well:
- Event-driven RabbitMQ architecture made scaling simple
- Redis deduplication kept crawl cycles clean
- Monitoring stack gave deep insights into performance
Next steps:
- Kubernetes support for cluster deployments
- Continuous Deployment with automated rollouts
- Dynamic proxy rotation for more realistic traffic simulation
Why This Matters
This project isn’t just about crawling Wikipedia — it’s a case study in distributed systems design:
- Independent, horizontally scalable workers
- Event-driven communication via queues
- Built-in monitoring and observability
- Real-world performance benchmarks
It’s a glimpse into how early search engines scaled — and a practical learning project for designing resilient, high-throughput systems.